
Accelerating Pub-Sub Systems using eBPF
Commentary on "Toward eBPF-Accelerated Pub-Sub Systems" Research Paper

Traditional pub-sub brokers like RabbitMQ or ActiveMQ run in user space, so each message must cross the kernel into user space for the broker, then back through the kernel again for every subscriber.
With many subscribers (large fan-out), all this back-and-forth adds a lot of overhead—causing extra latency (tens of milliseconds) and reducing throughput.
Now imagine if the broker didn’t have to make those trips at all.
Instead, it could run inside the kernel itself using eBPF, so messages could be routed directly without leaving the kernel. That cuts out the expensive context switches and data copies.
A recent research paper, Toward eBPF-Accelerated Pub-Sub Systems by Beihao Zhou, Samer Al-Kiswany, and Mina Tahmasbi Arashloo, caught my attention for several reasons.
It feels almost obvious — if we eliminate the repeated traversal of the kernel networking stack for every Pub/Sub message, throughput goes up and latency goes down.
But what really stood out to me is how the authors tackled message fan-out — taking a single publish and efficiently delivering it to many subscribers.
Let’s take it from the beginning.
Instead of pushing every message up into user space and back down again, their eBPF-based broker captures and forwards messages inside the kernel itself.
Compared to traditional user-space brokers, this approach is far more efficient — especially for applications where low latency and minimal delay in node-to-node communication are critical.
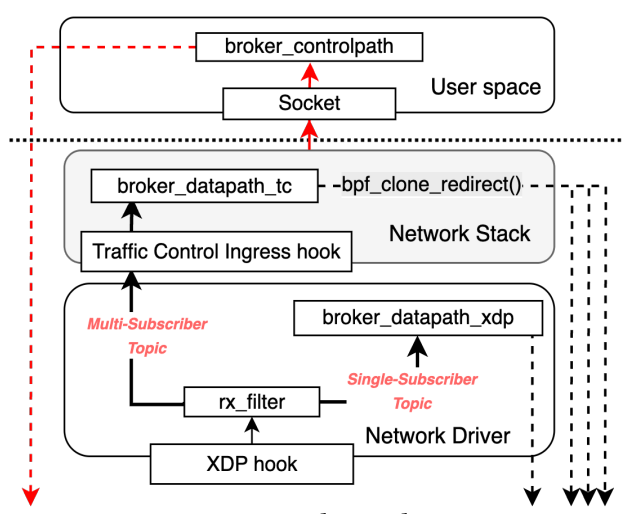
But in order for their eBPF broker to work, the authors had to overcome a few challenges to support different features and Pub/Sub use cases.
The first one is pretty straightforward — the broker needs to know where to forward messages once they’re published.
Subscriptions and topic registration aren’t performance-critical, so those can still be handled in user space. But the real trick is how to store that state inside the kernel, so message forwarding can happen entirely in eBPF.
But how?
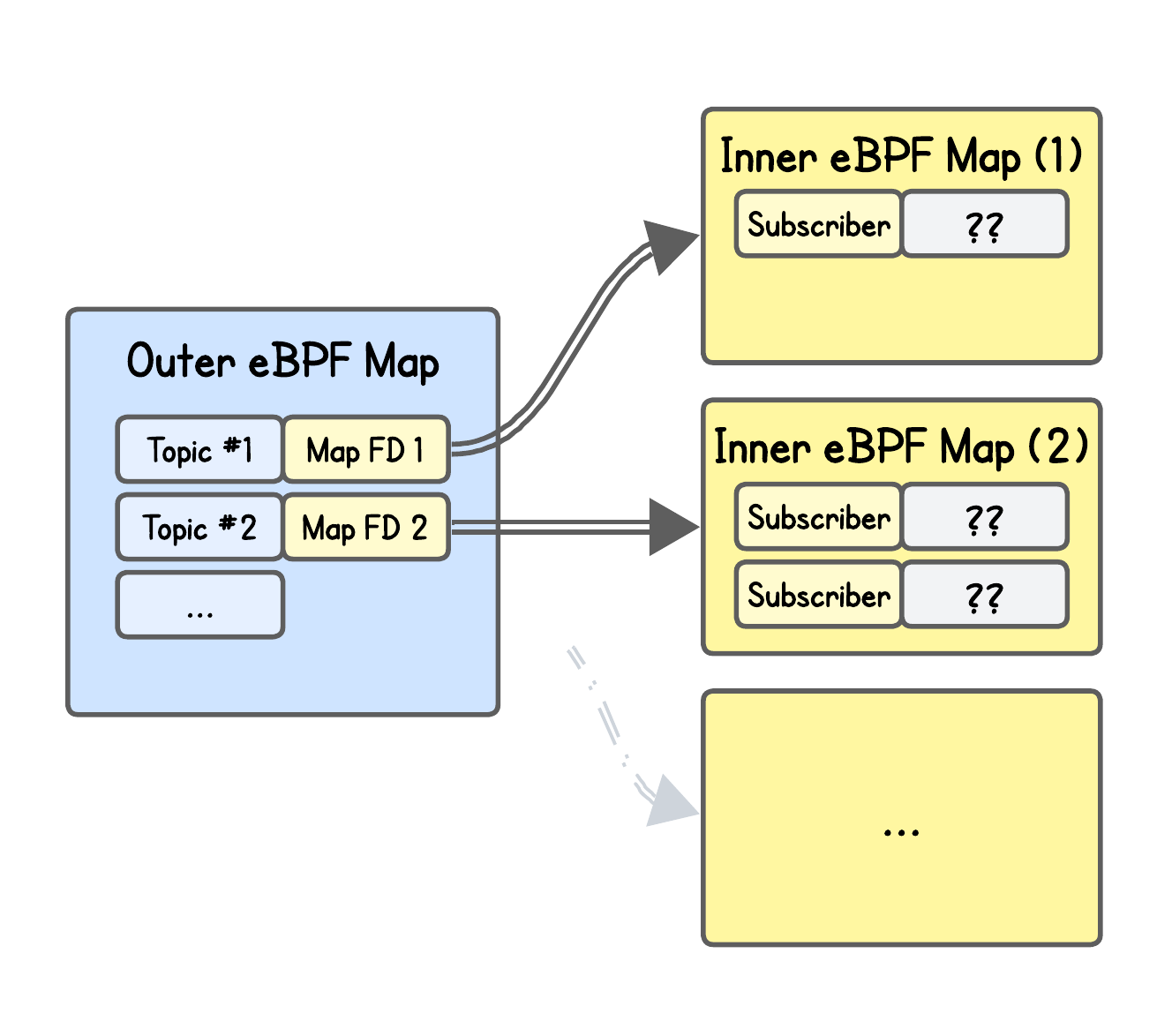
Using eBPF map-of-maps. That’s right — in eBPF you can nest maps inside other maps.
Specifically, they used BPF_MAP_TYPE_HASH_OF_MAPS, which consists of:
Outer eBPF map: a hash table where each key is a logical identifier (like a topic name in their case) and each value is a file descriptor pointing to an inner map.
Inner eBPF map: a regular map — in this case, a
BPF_MAP_TYPE_HASH— that stores the per-topic state. Each entry represents a subscriber (combination of source IP and port)
The authors don’t make a mention of any meaningful value stored in the inner map — which to some extent makes sense, since all they need is to know whether a subscriber exists for a certain topic, how many, and its IP/port, which is already encoded in the key.
They might also reserve the value for some future features.
💡 There’s also
BPF_MAP_TYPE_ARRAY_OF_MAPS, that works just likeHASH_OF_MAPSbut with an array as the outer map instead of a hash table. The keys are fixed integer indexes (0, 1, 2, …), rather than arbitrary identifiers.
But that’s only part of the puzzle.
Once the publisher–subscriber state is in the kernel, the question becomes: which eBPF program type to use to handle message forwarding?
The authors designed a two-part solution:
XDP hook (fast path):
Runs at the earliest point in the RX network path.
For topics with a single subscriber, it:
Parses the packet and extracts the Pub/Sub message.
Looks up the topic in the map.
Rewrites the IP/port headers and forwards with
XDP_REDIRECT.
If multiple subscribers exist, it calls
XDP_PASSto hand the packet up to the kernel, where the TC hook takes over.
TC ingress hook (fan-out path):
Handles multi-subscriber topics.
Does the same lookup but uses bpf_clone_redirect() to clone and enqueue the packet to each subscriber’s TX queue.
But why both?
XDP captures packets at the very start of the receive path, before most of the kernel networking stack comes into play. That means it can dispatch them earlier, with lower latency and less processing overhead than TC.
So conceptually, XDP should be the perfect place to run the broker.
But there’s a catch — XDP cannot clone packets and send it out to multiple subscribers. And this is almost always a must-have feature for any PubSub broker that needs to deliver one published message to multiple subscribers.
Therefore, the authors added a fallback method at the TC ingress hook.
In other words, whenever the XDP program detects that a topic has more than one subscriber, it passes the packet up to TC. There, the broker uses bpf_clone_redirect() to replicate the message and enqueue copies directly to the NIC’s transmit queues.
This isn’t a bad compromise: TC still bypasses the traditional protocol stack, sockets, queues, and user space.
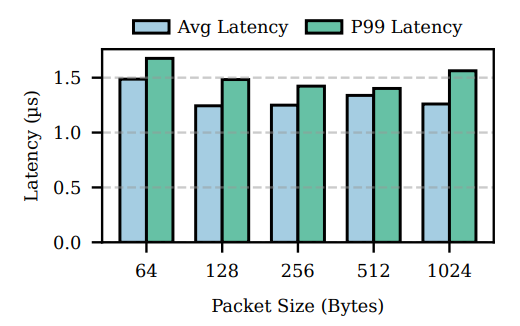
And while it does add slightly more overhead than XDP, the cost is tiny — on the order of 1 µs per packet, according to the authors’ measurements.
To evaluate the eBPF broker, the authors re-implemented the same Pub/Sub broker logic (baseline) in user space and compared the two.
And the results are quite impressive.
Throughput: Up to 3× higher than the user-space baseline under heavy fan-out.
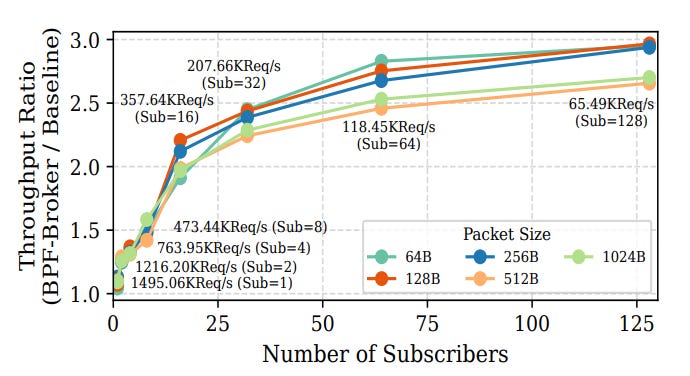
The figure shows the ratio of BPF-Broker’s throughput over the baseline across different packet sizes and subscriber counts.
Throughput here means the number of packets the broker both received and successfully fanned out to all subscribers.
Latency: Up to 2–10× lower, especially for small subscriber counts where user-space brokers pay high ingress cost.
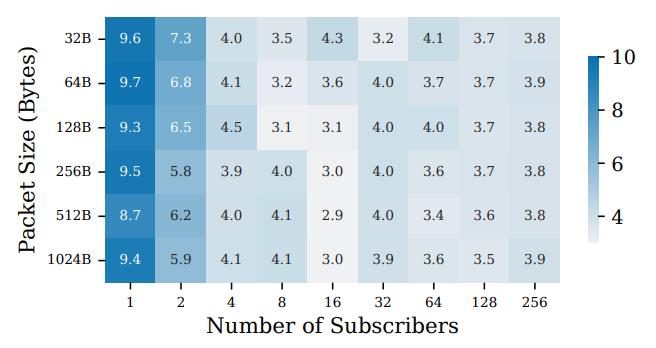
In fact, per-packet latency peaks at a 9.7× improvement (average ~4×). The largest gains occur at low subscriber counts (1–2), where the baseline wastes time moving packets through the kernel stack.
… This trend is further clarified for 1024B packets, where the baseline ingress latency is measured from the TC ingress hook until delivery to the UDP socket in user space. And the egress latency is from the first sendto() until all clones appear at TC egress hook (still slightly before it is dispatched).
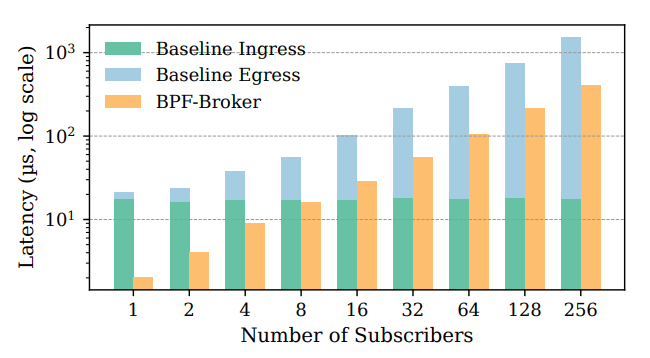
CPU utilization tells a similar story.
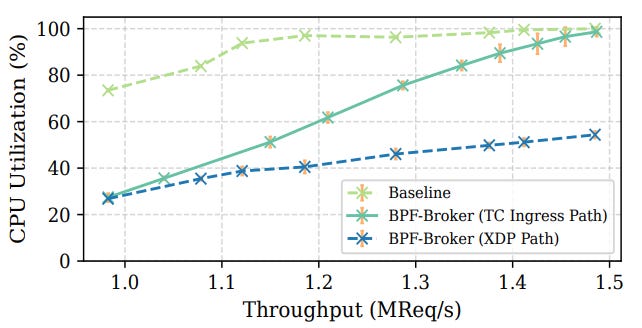
The user-space baseline quickly maxes out — over 90% per core at just 1.2 MReq/s, and fully saturated beyond that.
By contrast, the TC ingress path grows almost linearly with throughput, only nearing saturation at around 1.45 MReq/s. And the XDP path is obviously the most efficient of all, staying under 55% CPU usage even at the peak rate of 1.48 MReq/s.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find this resource helpful. Keep an eye out for more updates and developments in eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor
Thank you for the summary.
I saw the article on LinkedIn but did not read it yet. Thanks
But did you have the source code for an implementation related to the article ? Or maybe we’ll need to write it based on the article…