
Challenge 2: Concurrency Issues with eBPF Maps

Imagine a scenario where you monitor how many times your eBPF-based security programs block sensitive actions, such as attempts to execute binaries or elevate privileges to
sudo.These programs share a single eBPF map that stores a counter variable, along with a timestamp of the last update. Each time a security event is triggered, the counter is incremented, and the timestamp is updated to reflect the most recent event.
But what happens if two separate security events are triggered at the same time, both attempting to update the counter value in the eBPF map?
Or if an user-space application tries to read the counter value while an eBPF program is simultaneously updating it?
How can you ensure that your eBPF programs update the elements in a race-safe manner, ensuring no instance reads a partially updated structure?

The Solution
There are a few methods to avoid race conditions.
One method is to use atomic operations, such as __sync_fetch_and_add.
💡 Atomic operations perform specific tasks in a single CPU instruction, which is serialized at the hardware level, avoiding any race scenarios.
However, the limitation of this approach is that atomic operations only work on simple data types (1, 2, 4, or 8 bytes) and trying to use them on a structure with multiple field would require multiple atomic instructions in sequence (one for each element). This, in turn, could lead to partial updates of the structure, which we want to avoid.
In other words, this approach cannot safely update our struct shared_data, which contains both a counter and the timestamp of the last update.
To fill this gap, eBPF provides support for spin locks!
Spin locks allow you to safely update multiple related fields in a structure and release the lock only after all operations are complete.
Here's a simple code snippet of the solution:
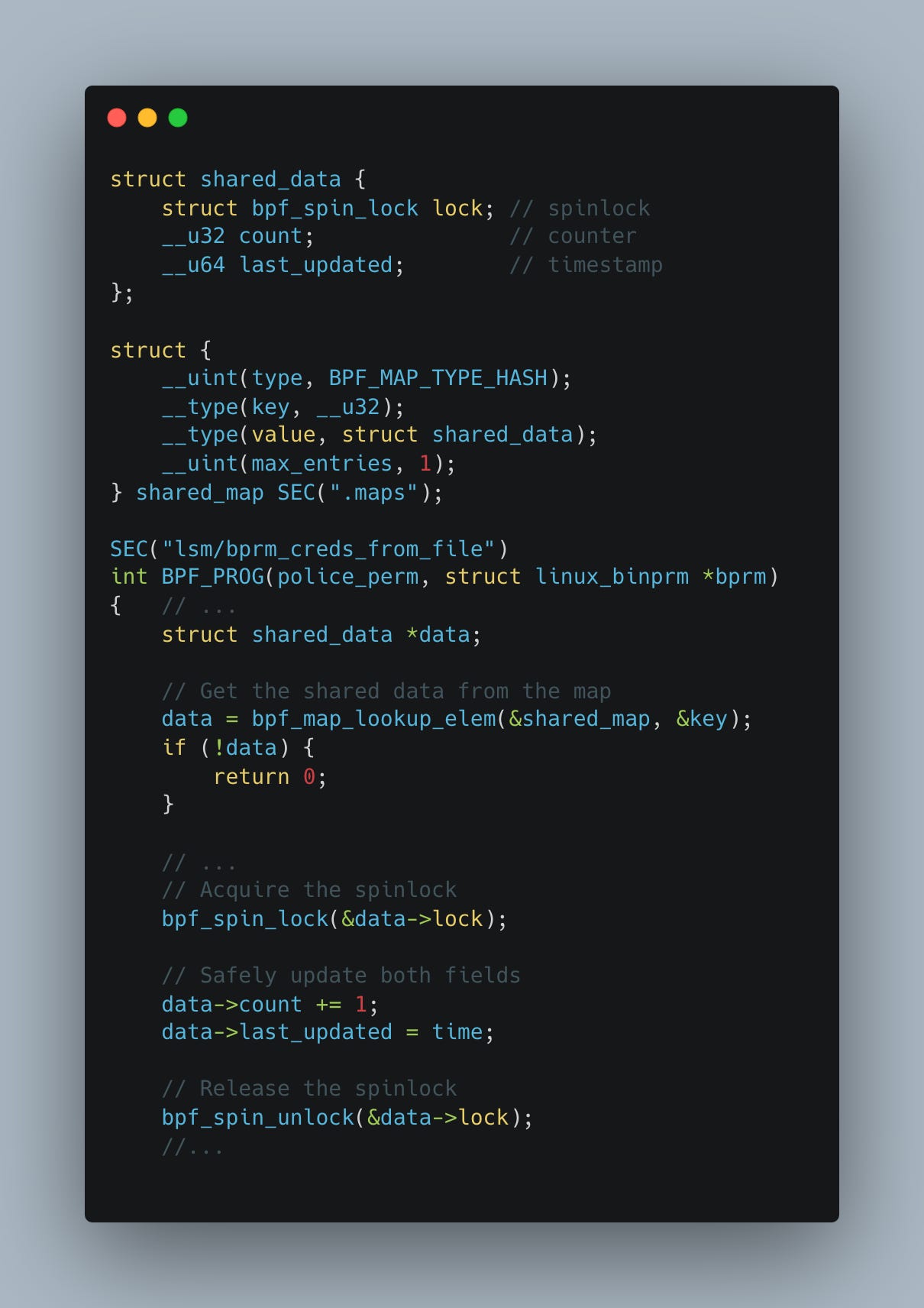
To implement a locking mechanism, we need to follow three steps:
Add a
structbpf_spin_lockto the struct we will be modifying.Acquire the spinlock before updating fields in the struct using
bpf_spin_lock.Release the spinlock once all operations on the struct are complete using
bpf_spin_unlock.
In fact, we can also safely update the struct from userspace. In ebpf-go, this is achieved using the ebpf.UpdateLock flag, which you can see in the code available on my GitHub repository.
❗️Not all BPF program types support
bpf_spin_lockso be sure to check the supported program types list.
I find code example renders in Substack tedious, so I’ll refer to my GitHub repository with the complete code.
Here’s the link.
⭐️ Bonus Solutions
Another way to solve this issue is by using Per-CPU maps. These are map types that maintain a separate copy of the map for each logical CPU.
By allocating memory per CPU, we eliminate the need to synchronize memory access since each CPU only writes to its own copy, avoiding shared access entirely.
This is the most CPU-efficient approach for handling race conditions in write-heavy workloads, as it reduces synchronization overhead.
However, this method comes with a memory cost, as the required memory scales with the number of logical CPUs (map_size * CPUs). It also adds complexity on the userspace side, since data must be read from each CPU's map individually and then combined together (e.g. sum of all count on all CPUs).
In certain niche use cases, it may be possible to leverage eBPF's built-in Read-Copy-Update (RCU) logic, which is more suitable for read-heavy workloads. I’ll cover this in a future newsletter.
⏪ Did you miss the previous challenge? I'm sure you wouldn't, but JUST in case:

I hope you find this resource as interesting as I do. Stay tuned for more exciting developments and updates in the world of eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor