
Rewiring the 5G Data Plane: XDP/eBPF and UPF
eBPF and 5G Data Planes

In 5G networks, the User Plane Function (UPF) plays a central role in packet routing, QoS enforcement, and policy application.
Think of it as a (smart) traffic cop inside 5G that quickly tells your phone’s data which road to take so everything you do online feels fast and smooth.
And traditionally, the UPF runs in user space, pushing packets through the kernel’s network stack—incurring extra latency from context switches, memory copies, and system‑call overhead.
Meanwhile, soaring application‑performance expectations and an explosion of connected devices—from IoT sensors to smartphones—demand ever‑lower latency and higher throughput.
So we asked ourselves — could eBPF help operators keep up with these demands?
🚀 Special thanks to Satyam Dubey, Software Engineer at NgKore, for putting together this practical guest post for eBPFChirp!
To understand where eBPF could really make a difference, it helps to break down what the UPF actually does inside the 5G core.
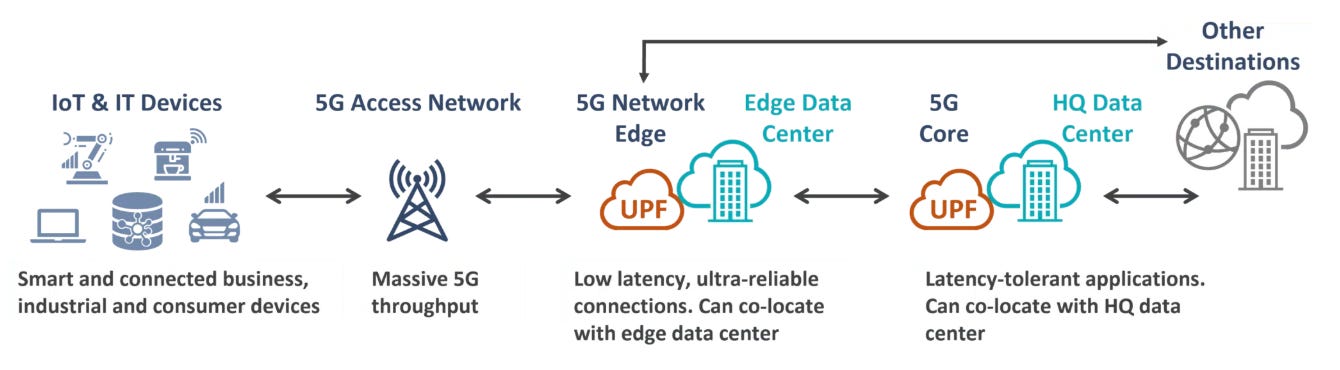
In practice, one UPF instance is responsible for a handful of high-speed, network packet-level jobs:
GTP-U tunneling / de-tunneling: Encapsulates or decapsulates each network packet such that it can travel through the 5G core on the right path.
IP forwarding / NAT: Sends the packet to the correct destination and, if needed, swaps private IPs for public ones.
QoS and policing: Makes sure high-priority traffic (video calls, mission-critical data) gets the speed and low delay it needs.
Lawful Interception: Creates a copy of selected traffic for legal authorities—quietly, without disrupting the user’s session.
Traffic classification: Looks at packet headers to decide whether to keep traffic in the core, send it to the edge, or apply a special rule.
Usage metering: Counts how much data each user or service consumes so operators can bill or track usage.
And now just think about the rapid growth of IoT devices or more to say, industrial sensors, smart cities, autonomous cars and so forth.
It’s an inevitable fact that a modern UPF must become even more performant — it must adapt, scale, and perform under more diverse workloads.
Here are the 10 characteristics of an ideal UPF:
Ultra-Low Latency (URLLC): Sub-millisecond packet processing for mission-critical, real-time applications.
High Throughput: Multi-Gbps capacity with minimal per-packet overhead.
Dynamic Programmability: On-the-fly insertion of new policies, metering rules, traffic-shaping functions, DPI hooks, and more.
Efficient Flow & Session Management: Fast GTP-U tunnel handling and PFCP session control (FAR, QER, URR) via lightning-quick table lookups.
Strong Security & Slice Isolation: Built-in ACLs, per-slice enforcement, anti-spoofing measures, and rate-limiting safeguards.
Rich Observability & Telemetry: Native tracing, flow accounting, and metrics export for Prometheus, Grafana, or other monitoring stacks.
Hardware Agnosticism: Optimized for standard NICs—no dependency on specialized SmartNICs or DPDK-exclusive setups.
Resilience & Fault Tolerance: Graceful failover, zero-loss upgrades, and healing under node or link failures.
So where does it fall short?
Most legacy or software-based UPFs process traffic at the user-space, which means all the network traffic before being processed goes through:
Traversing the full kernel networking stack: routing, tc, Netfilter, etc.
Allocating and copying
sk_buffbuffers for each packet transitionContext-switching between kernel and user space to apply policies or forward traffic
And while this may seem all super performant, it actually has a significant impact on applications (or I should say devices) that require:
High Latency since the traversal of the packets through the Kernel Networking Stack adds extra microseconds per packet.
High Throughput since the CPU quickly saturates at high packet-per-second (PPS) rates, capping multi-Gbps “ambitions”.
Operators have already thought about these downsides to some extent and Data Plane Development Kit (DPDK) was introduced to overcome the kernel overheads by performing Kernel bypass via forwarding the packet directly as it received on the network card to the user space where it is processed.
However, DPDK has some major limitations:
Hardware dependency: Requires NICs with DPDK support (e.g.,
vfio-pci,uio)Limited Observability: Doesn’t integrate well with Linux tools or observability stacks
Rigid Scaling: Hardware-specific scaling bottlenecks, poor elasticity
And all of this brings us to eBPF.
We are not gonna go into to much details about eBPF, but in particular of our interested is the XDP (eXpress Data Path) eBPF program type.
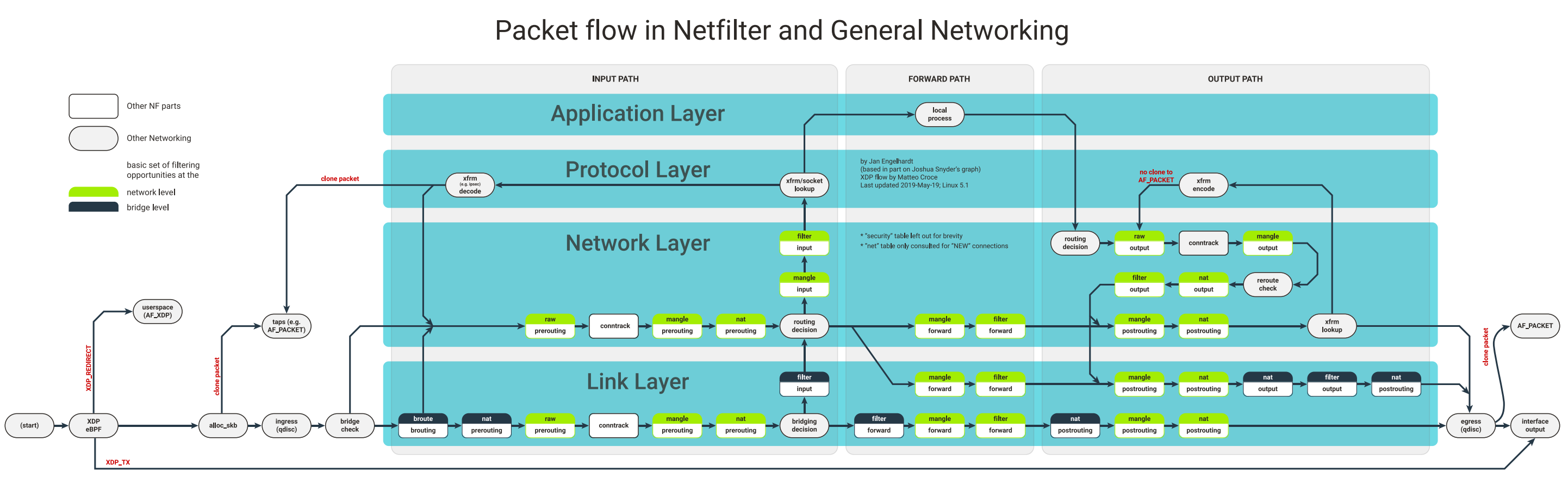
If you look at the image to the very left of the diagram you’ll notice the XDP/eBPF block right after the (start) point.
This is where XDP hooks into the Network Interface Card (NIC) driver — so before the packet is even handed off to the kernel via alloc_skb().
In other words, it’s the earliest and fastest possible interception point for packet processing in Linux.
So why would this matter to you?
By using eBPF XDP program you can:
Bypass costly layers like Netfilter, qdisc, allocation of
sk_buffand the full routing logic.Implement line-rate filtering, DDOS mitigation, or even packet routing logic directly from the NIC driver.
This is what makes eBPF/XDP-based UPFs orders of magnitude faster than traditional userland UPFs that rely on Kernel stack, or Netfilter hooks.
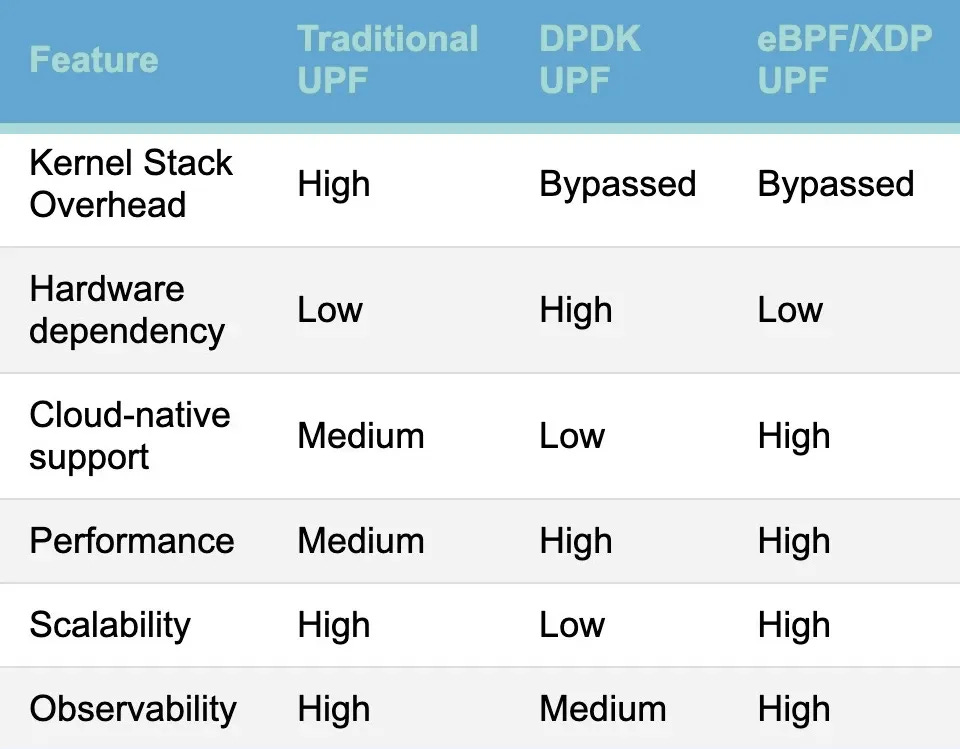
But that’s the theory.
To support these statements, let’s look at a benchmark comparison of edgecomllc eupf, Open5gs-UPF , Free5gc-UPF and UPG-VPP.
Benchmark steps and results are available in the following GitHub repository.
Some key take-aways:
Processing model matters: Keeping packets in kernel space (eBPF/XDP) or binding NIC queues directly to poll-mode drivers (DPDK/VPP) eliminates the syscall/context-switch tax that holds back user-space TUN/TAP designs.
eUPF leads on sheer bandwidth: It sustained ~9.6 Gbps in both directions—about 6–8× more than Open5GS and ~30% more than UPG-VPP—while running entirely with eBPF programs attached to XDP.
UPG-VPP is latency king: Its 0.157 ms mean delay beats the others by ~25% thanks to DPDK’s busy-polling datapath, even though the VM-level virtio interface capped total goodput below line-rate.
free5GC strikes a balance: By pushing GTP handling into a kernel module it outperforms Open5GS by roughly 4×, but still trails the DPDK/eBPF contenders once packet rates climb above ~500 kpps.
User-space TUN/TAP is the limiting factor for Open5GS: Every packet makes two copies and a context switch, so performance tops out near 1.2 Gbps; good enough for small-lab 5GC demos but not edge deployments.
Use these results as a directional guide: for line-rate N6 and low jitter, start with eUPF or UPG-VPP; for quick functional setups stick with Open5GS; and for a middle ground consider free5GC’s kernel UPF.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find this resource helpful. Keep an eye out for more updates and developments in eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor and Satyam