
Why Does My eBPF Program Work on One Kernel but Fail on Another?
How to Build Truly Portable eBPF Programs

In a perfect world, everyone’s systems would be fully updated, patched regularly, and running the latest kernel.
But let’s be real—that’s rarely the case.
Some environments still rely on legacy versions of Ubuntu or Fedora, while others don't even have their kernels compiled with BTF (BPF Type Format) support.
And if you’re maintaining any open-source tools, things get even messier. You have zero control over what kind of system your users will run your program on.
All of this makes it tricky to ensure that your eBPF programs can run reliably across different distributions, ultimately affecting whether your eBPF tool gets adopted or not.
So how do we make eBPF programs truly portable?
To better understand the problem, let’s look at an hypothetical example.
Suppose you compile an eBPF program on kernel version 5.3, but it fails to run on 5.4.
Why? Because each kernel version ships with its own kernel headers, which define structs and memory layouts. Even small changes in these definitions can break eBPF programs.
Take structs, for example. Let’s say we have one representing a TCP header in kernel 5.3:
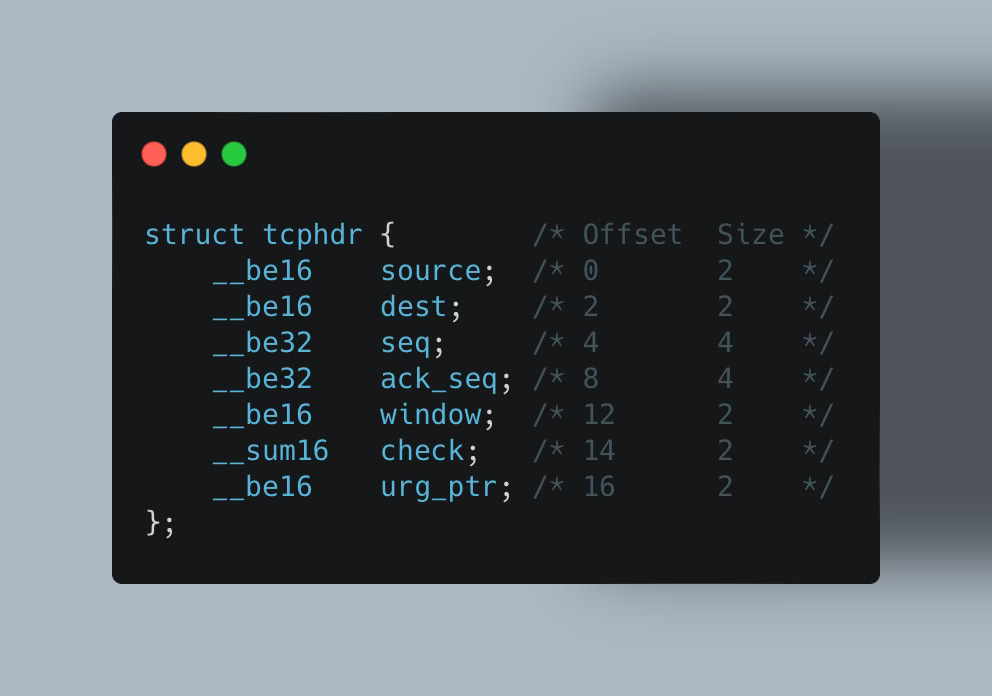
In the next kernel release, 5.4, kernel developers might decide to place these fields into a new struct or rename the seq field to seque or perhaps move these fields up or down (changing their offset):
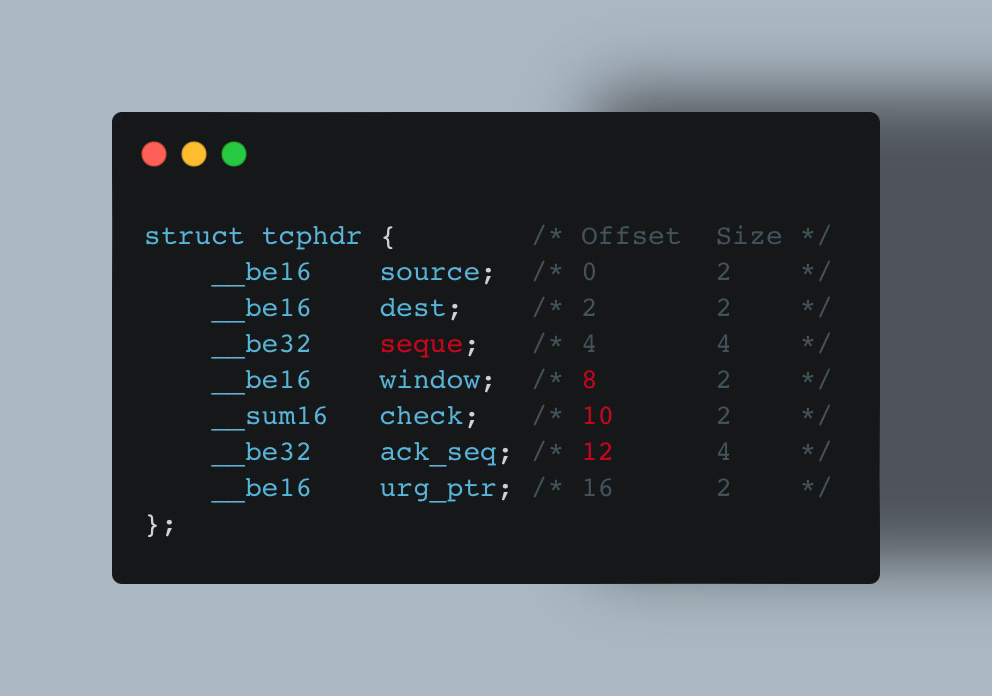
See the problem?
Your code may rely on specific fields or offsets, which are likely to change across kernel versions.
Since the eBPF program itself has no control over these changes, there’s an inherent need for a solution to ensure the portability of eBPF programs.
If you search online, you'll find plenty of resources recommending the use of BPF CO-RE (Compile Once – Run Everywhere) to address this issue.
In other words, rather than writing your programs like this:

You should replace the BPF_PROBE_READ() family of helpers with the BPF_CORE_READ() family, which enables access to struct fields in a way that adapts across kernel versions:

In short, the BPF_CORE_READ() family of helpers enables relocatable reads of kernel structs.
So if a certain struct field (like filename in the example) sits at a different offset in another OS or kernel version, these helpers can still locate and read it correctly.
Under the hood, this is made possible by BPF CO-RE relocation information and BTF (BPF Type Format).
Wait, what? CO-RE relocation information? BTF?
If you peek into almost any production eBPF codebase, you’ll notice all of them include the vmlinux.h header.
This file contains definitions for all kernel structs like trace_event_raw_sys_enter in the example above, generated based on the currently running kernel.
💡 You can generate this header file using:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Here’s where it gets interesting — this header includes a few special lines at both the top and bottom:

At the top of vmlinux.h, you'll notice the line __attribute__((preserve_access_index)) which tells the compiler to emit BPF CO-RE (Compile Once – Run Everywhere) relocation information for every struct field your eBPF program accesses into your eBPF object file.
In other words, when you reference a field (like filename in the example) from a kernel struct, the compiler doesn’t just hardcode its offset. Instead, it records metadata—like the field’s name, type, offset, and parent struct within bpf_core_relo struct.
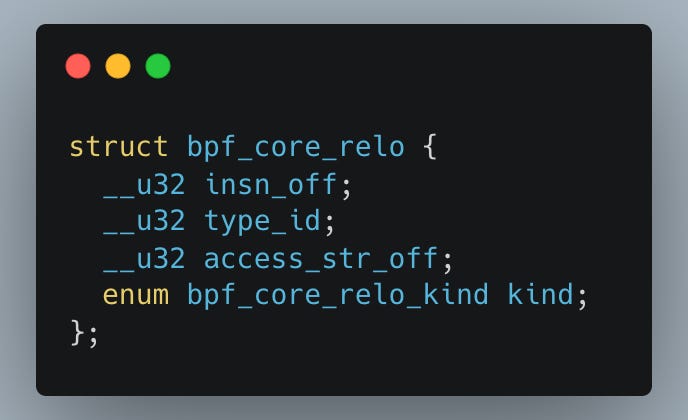
The clang attribute push ensures this applies to all struct definitions until the matching clang attribute pop at the end of the file.
The BPF CO-RE relocation structure (or relocation information, if you prefer) includes the following fields:
insn_off: Identifies the instruction being relocated, such as one that sets a register to a specific value.type_id: References BTF (BPF Type Format) metadata, which describes the layout of the target kernel structure.access_str_off: Specifies how a particular field is accessed relative to the structure.
For the tracepoint example above, the BTF information looks like this:

And for your eBPF program to work across kernel versions—where struct layouts may differ—the target kernel must also be compiled with BTF support. Without it, the program won’t be able to resolve the correct fields offsets at runtime.
Why is this necessary?
When your eBPF program is loaded by a BPF loader like libbpf, the loader compares the program’s BTF data with the target kernel’s BTF. It then resolves types, updates offsets, and adjusts field accesses to ensure the program reads kernel variables correctly.
This process is known as field offset relocation.
One subtle limitation of this approach is that tools relying on BTF data implicitly depend on the target kernel being compiled with BTF support.
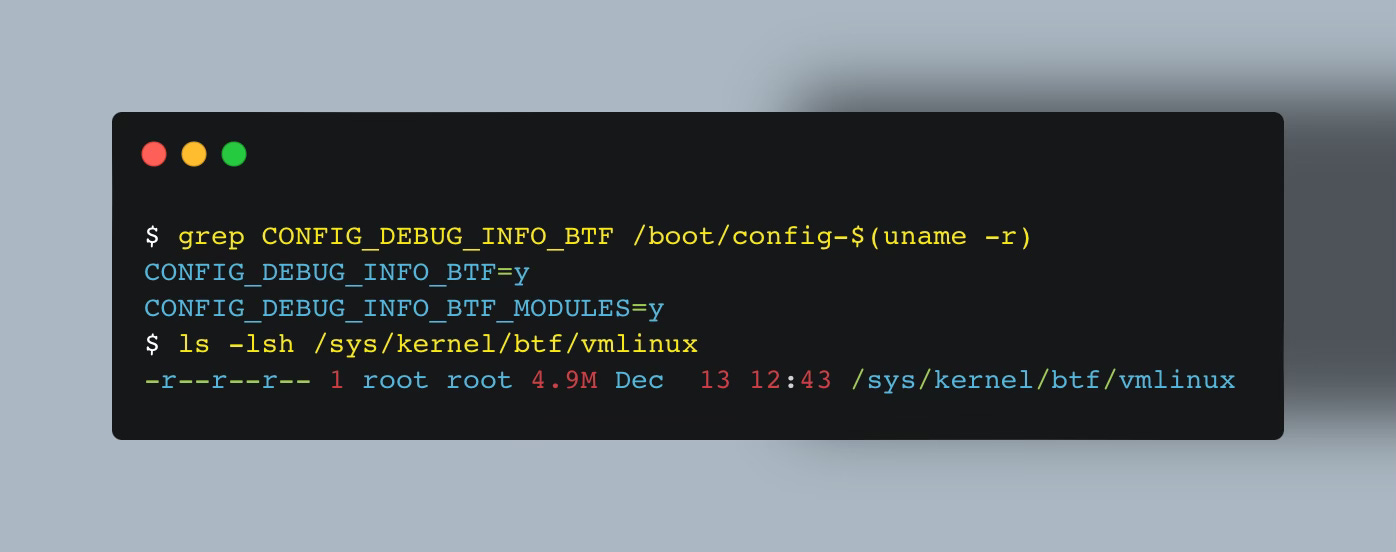
Without BTF support in the target kernel, the loader can't perform field offset relocation, and the program may fail to load or behave incorrectly.
But can we do something to avoid this dependency?
Actually—yes.
Let me show you how.
Aqua Security maintains a repository called btfhub-archive, which provides prebuilt BTF files for a wide range of kernels that lack embedded BTF.
You can download the relevant BTF files for the kernels you want to support and embed them directly into your eBPF program—eliminating the need for BTF support on the target system entirely.
I could stop here and show you a simple example of how it’s done—but I’ve taken it a step further.
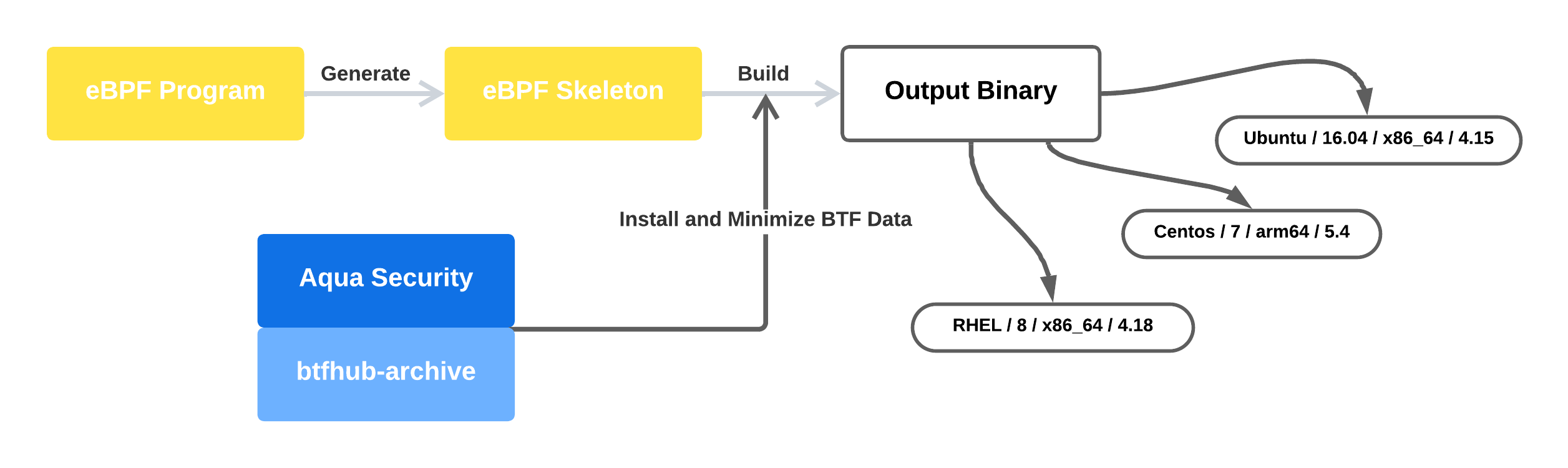
In my GitHub repository, I’ve built a complete solution that:
Generates an eBPF skeleton for my example program
Automatically downloads and embeds BTF data from
btfhub-archivefor all kernel/OS versionsMinimizes the BTF data to include only the types actually used by the example eBPF program
Produces a single binary that can run across a wide range of kernels—without requiring BTF support on the target system
I’ve included plenty of details and helpful comments in the repository, so be sure to check it out if you want to dive deeper or adapt it for your own use.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find this resource helpful. Keep an eye out for more updates and developments in eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor