
Challenge 3: eBPF Ring Buffer Optimizations

Consider an eBPF XDP program that captures network packets and sends their metadata like source IP and port to user-space application through a Ring Buffer.
But what happens if the rate of captured packets metadata exceeds the rate at which your user-space application can process them?
Or if the number of captured packets is generating too much load on the system due to the amount of processing?
How would you approach mitigating these challenges?
What strategies can be employed to optimize “data flow” between user space and kernel space, reduce the system load, and prevent packet loss?
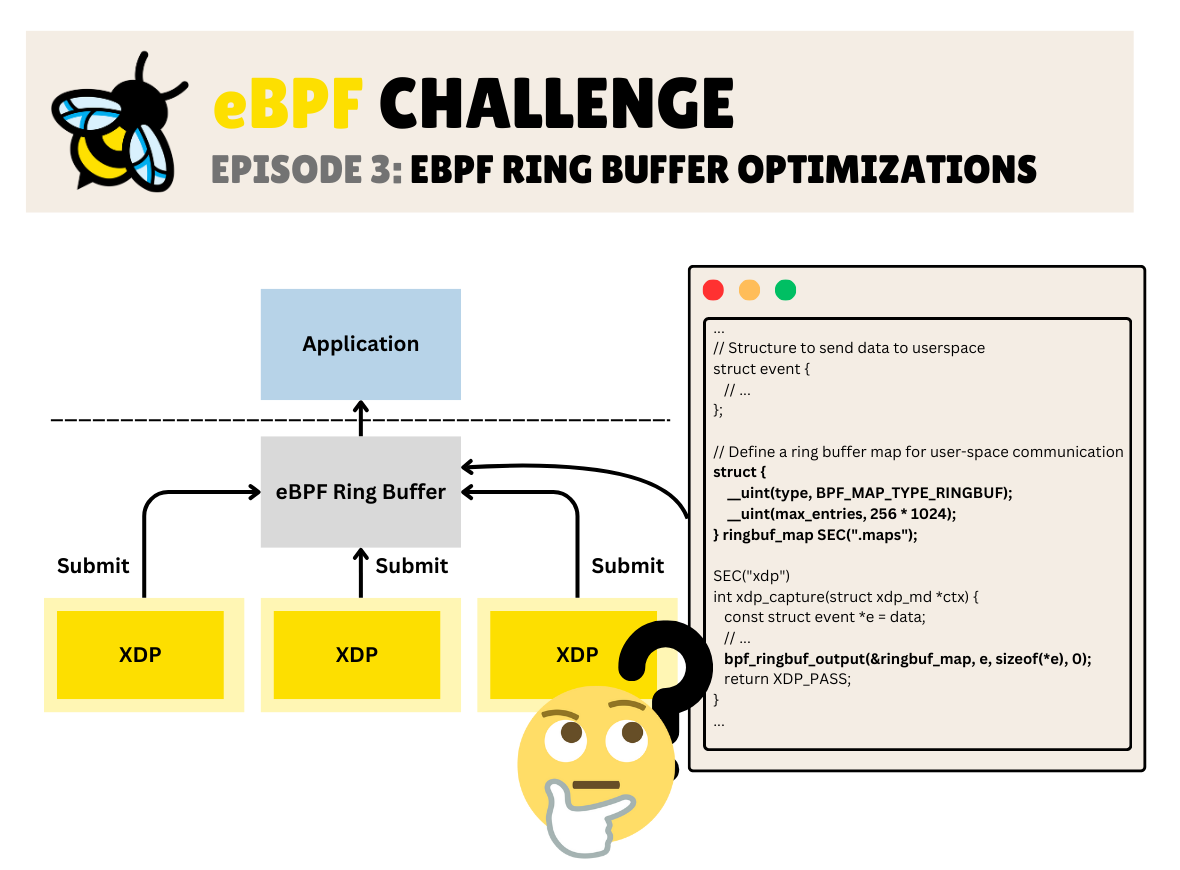
The Solution
There are multiple ways to approach this.
First, you can spawn a goroutine (Golang-specific) for each captured packet's metadata, allowing parallel processing and preventing the main packet-consuming process from blocking.
💡 Note: The Ring Buffer uses a Multiple Producer, Single Consumer (MPSC) approach, allowing only a single consuming process to safely manage the head pointer for reading data.
For instance, assume the user-space processing loop takes approximately 0.2 seconds to complete before it can consume the next packet's metadata.
This delay is intentionally introduced in the code; but reflects e.g. the time needed to generate statistics from the metadata.
If your application uses a single eBPF Ring Buffer consumer process for consuming and processing packets metadata, it takes approximately 200 seconds to process 1,000 packets while utilizing:

However, if the consuming application spawns a goroutine for each captured packet, the processing time is reduced to 2.3 seconds while utilizing:

The test script can be found in
test.shinvolving 1000 requests to a simple HTTP server.
While we observe a slight increase in average CPU consumption with more consumers, the primary benefit of this approach is the significantly faster consumption of captured packets from the Ring Buffer — up to 100x faster according to our tests.
However, this only partially addresses the issue.
During network traffic spikes, the high volume of captured packets can still overwhelm the system, leading to data loss as the Ring Buffer discards packets to cope with the load.
To address this, we can take an inspiration from Netflix and their "Noisy Neighbor" problem.
💡 The Noisy Neighbor problem occurs when a service uses excessive resources on a multi-tenant host.
Netflix monitors their services using eBPF programs, but the high volume of events from their large user base would overwhelm the system.
To prevent this, they enforce a rate limit in their eBPF programs that forwards kernel events (through the Ring Buffer) to their observability solution ONLY every X milliseconds, while the rest of the events is not taken into an account.
Fewer data mean less processing is required, resulting in lower CPU consumption.
But to be frank with you, this delves down to what your observability stack is OK with.
It might be infeasible to sample only few packets and it’s better for you to create a separate Ring Buffer for these high-frequency events at a cost of higher CPU consumption.
Ultimately, the choice of sampling or having multiple Ring Buffers comes down to what your application stack can tolerate.
Code solutions are available at the link below.
Additionally, if your Ring Buffer is at risk of dropping data, you can further improve the solution using the Ring Buffer Reserve/Submit API.
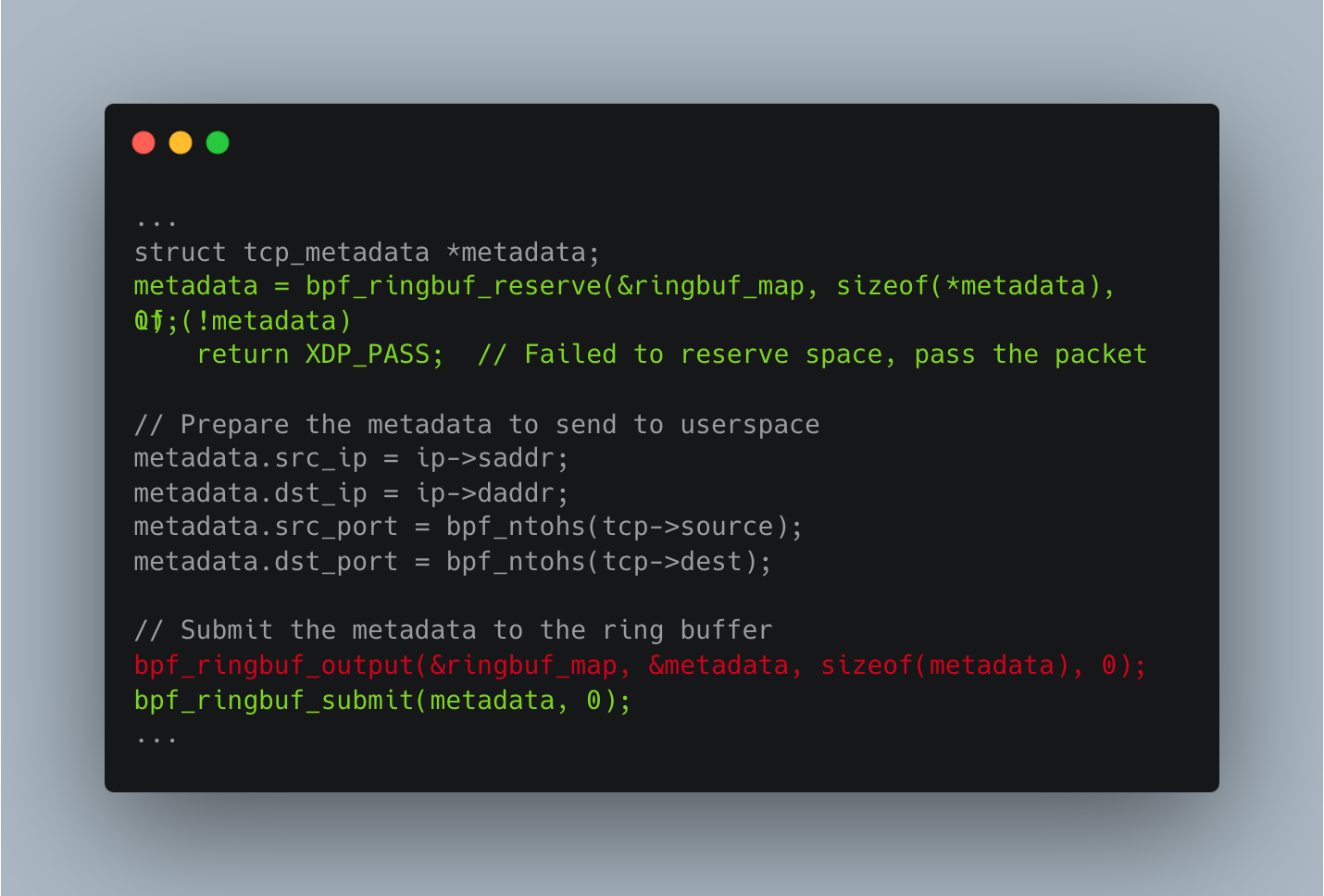
This way, if the Ring Buffer is full, the eBPF program finishes early, conserving CPU cycles.
I find code example renders in Substack tedious, so I’ll refer to my GitHub repository with the complete code.
Here’s the link.
Before you head out, let me know what you think by casting your vote in the poll:
⏪ Did you miss the previous challenges? I'm sure you wouldn't, but JUST in case:


I hope you find this resource as interesting as I do. Stay tuned for more exciting developments and updates in the world of eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor
Hey Usama, this is a good point, but I guess the confusion steams from how I formulated the sentences.
In fact, there is a single consumer process, but for every event the data is dispatched to a separate goroutine, causing the main process to NOT block and immediately be able to consume another event.
I will update the post to avoid the confusion. Thank you for pointing that out.
Your first solution seems to be incorrect. Ringbuffers follow a multiple producer - single consumer model [1]. For one ringbuffer there can be only a single userspace consumer because the consumer is responsible for managing the head pointer into the ringbuffer which is used to begin reads of new data.
Using multiple consumers over a single ring buffer will leads to all kinds of bugs, and corrupted data.
[1] https://github.com/torvalds/linux/commit/457f44363a8894135c85b7a9afd2bd8196db24ab