
When TCP Window Scaling Broke Our API — and How I Solve It with eBPF
Solving a 2AM Production Outage

It was 2:03 AM when my phone buzzed with the familiar dread of a PagerDuty alert.
Half-asleep, I squinted at the screen:

What started as another routine midnight fire drill would become one of the most educational debugging sessions of my career. And yet another testament to why eBPF has become indispensable in my observability toolkit.
🚀 Special thanks to Shankar Malik, Governing Board Member Committer Representative at Linux Foundation, for putting together this deep and practical guest post for eBPFChirp!
After stumbling to my laptop with coffee in hand, I dove into our monitoring dashboards. The metrics painted a confusing picture:
CPU utilization: Normal (~30% across all instances)
Memory usage: Well within limits
Database performance: Query times looked healthy
Load balancer metrics: Even distribution of traffic
Application logs: No obvious errors or exceptions
Yet our API was collapsing.
Response times that normally sat around 200ms were spiking to 30+ seconds before timing out.
The pattern was insanely random—some requests sailed through while others hung indefinitely.
And I’ve tried my best using traditional approaches.
Dead End #1: Application Layer Investigation
My first instinct was to blame the application.
I examined recent deployments—nothing had changed in 72 hours.
I scaled up our API instances, thinking we might be hitting some hidden bottleneck.
No improvement.
Dead End #2: Database Deep Dive
Next, I suspected database connection pooling issues.
Our PostgreSQL metrics looked clean, but I increased the connection pool size anyway.
Still nothing.
Dead End #3: Cloud Provider Rabbit Holes
Maybe it was the cloud provider?
I checked AWS status pages, examined ELB metrics, and even opened a support ticket.
Everything appeared normal from their perspective.
At 5:47 AM, fueled by frustration and my fourth cup of coffee, I had an epiphany.
What if the issue wasn't what we were monitoring, but where we were monitoring?
All our observability focused on application metrics and infrastructure resources.
But what about the network layer?
What if packets were getting lost, delayed, or malformed somewhere between our load balancer and application instances?
Instead of guessing what might be wrong, eBPF allows me to see exactly what was happening to every packet flowing through our system. And so I did.
First, I established a baseline with traditional packet capture:
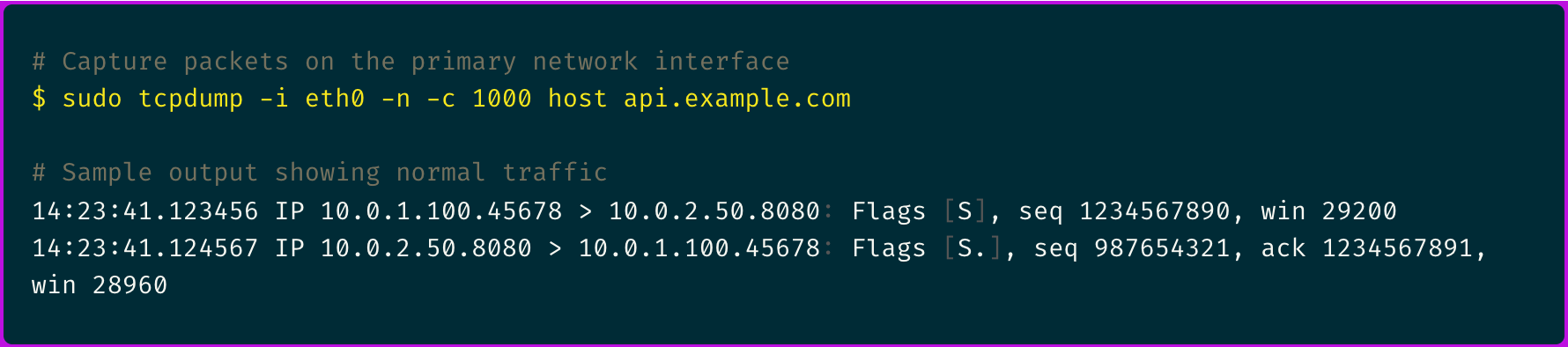
The three-way handshake looked normal, but I needed deeper visibility into what was happening after the connection was established.
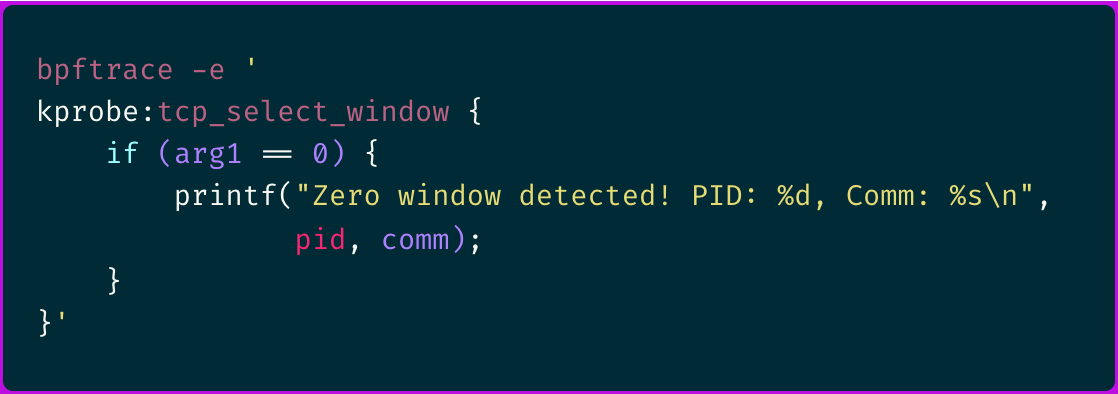
Using bpftrace, I created a custom probe to monitor TCP window sizes and scaling factors:
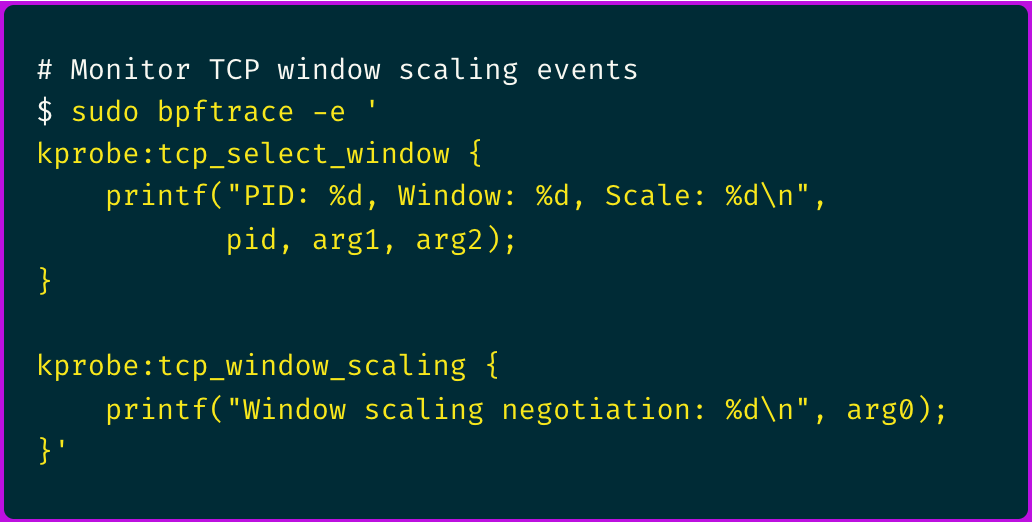
The output immediately revealed something suspicious:
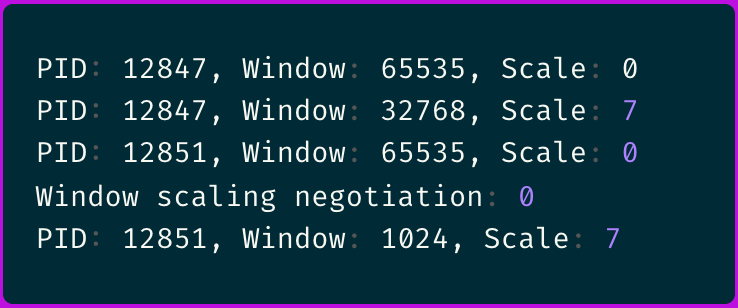
The inconsistent window scaling caught my attention.
So I deployed a more sophisticated eBPF program using the BCC toolkit:
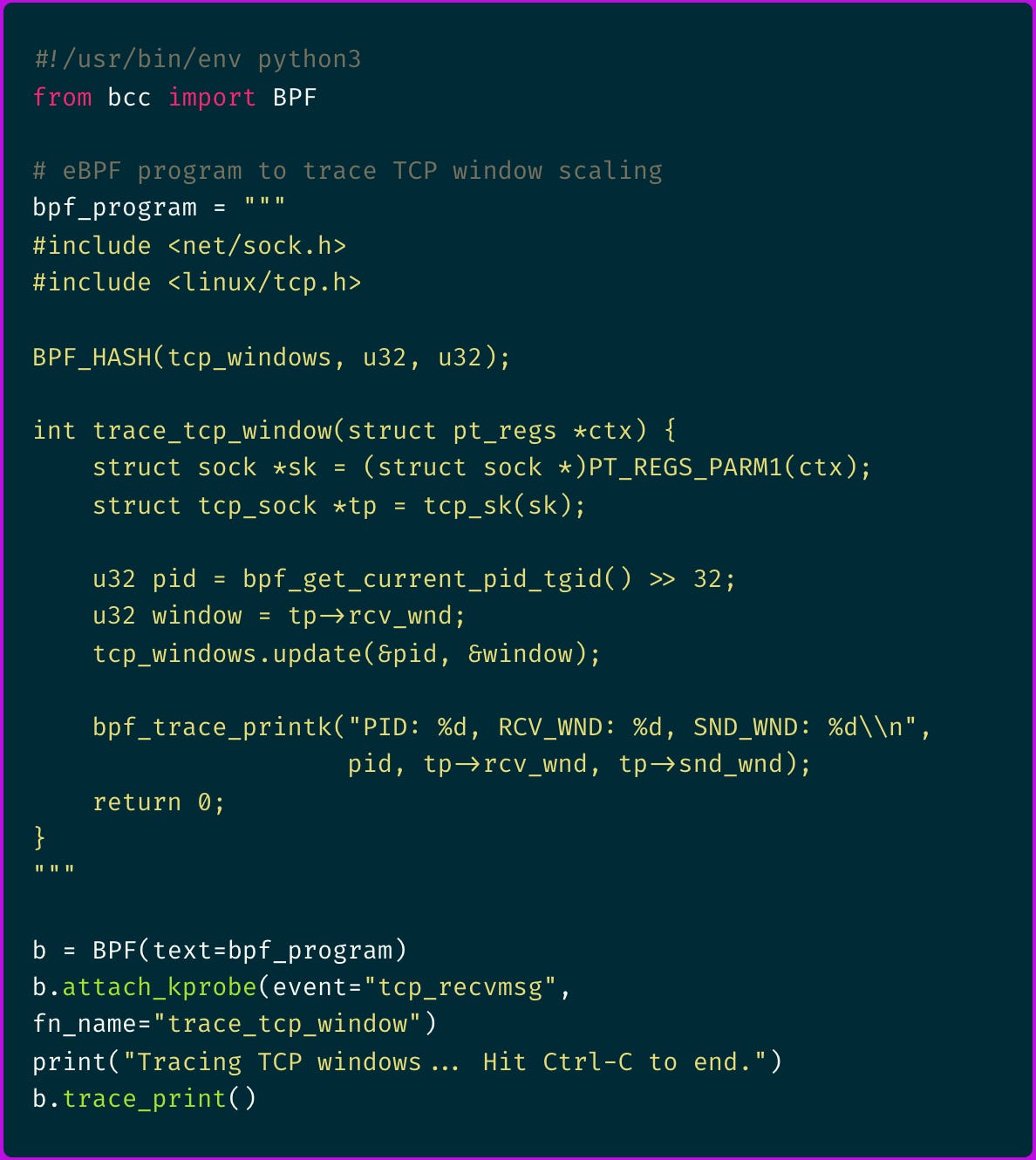
Running this revealed a clear pattern:
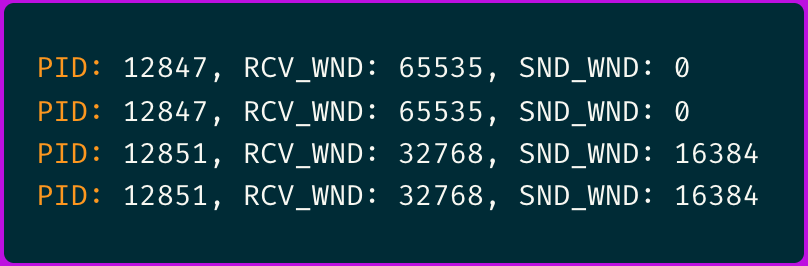
The eBPF traces revealed that some connections were negotiating window scaling correctly while others weren't.
And ever more important, I noticed that failing connections consistently showed a sender window (SND_WND) of 0, indicating the receiver had advertised a zero-byte receive window.
Understanding the Root Cause
TCP window scaling allows connections to use receive windows larger than 64KB by applying a scaling factor. Here's what was happening:
Normal flow: Client connects → Window scaling negotiated → Large windows enable high throughput
Broken flow: Client connects → Window scaling fails → Small windows cause throughput collapse
The issue stemmed from a recent kernel parameter changed on our load balancer nodes:
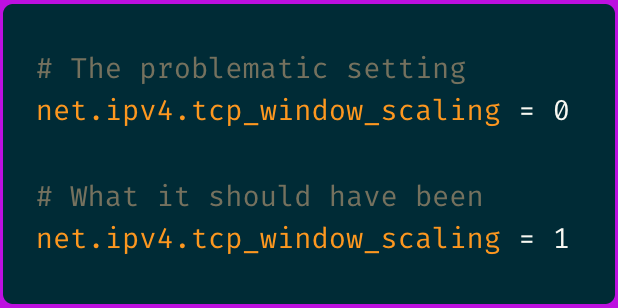
With window scaling disabled on the load balancer but enabled on the application servers, we had a TCP window scaling mismatch:
Client connects to load balancer (no window scaling)
Load balancer forwards to app server (expects window scaling)
App server's large receive buffers get constrained by the non-scaled window announcements
Effective window size drops to ~1KB instead of the expected 64KB+
High-throughput requests stall waiting for tiny window advertisements
And although it took me a relatively long to get to here, the fix was embarrassingly simple:
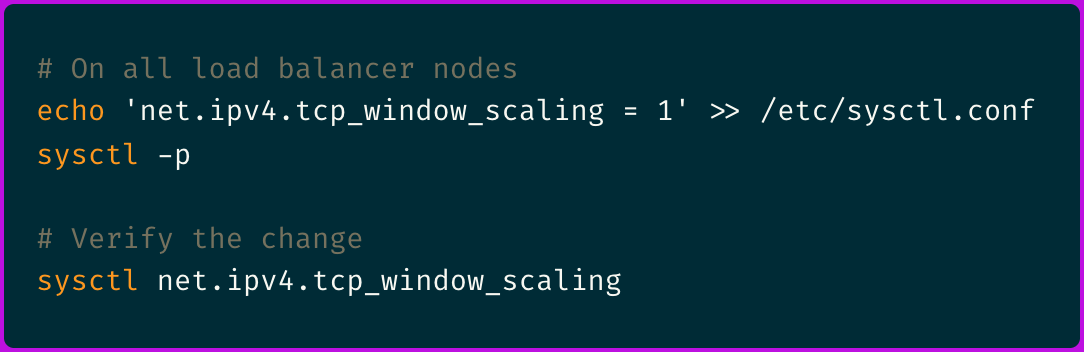
Within minutes of applying this change, our API response times dropped back to normal. The 95th percentile went back from 30+ seconds to under 300ms.
So why this this happened at all and how I prevented it from re-occurring?
This is more or less specific to our setup, but the root cause traced back to a well-intentioned security hardening script that had disabled TCP window scaling across our infrastructure.
And while this might make sense for certain security-sensitive environments, it's generally counterproductive for high-throughput applications.
And our application-layer monitoring couldn't see this issue because:
CPU and memory usage remained normal - the applications weren't working harder
Connection counts looked healthy - TCP connections were established successfully
Application logs showed no errors - from the app's perspective, it was just waiting for slow clients
The problem lived in the kernel's network stack, invisible to traditional observability tools.
And eBPF filled the observability gap for this specific issue using:
And if that wouldn’t work, in the next steps I would probably try:
tcpconnect – traces every outgoing
connect()attempt, showing which process opens a new TCP connection and to what address/port.tcpaccept – records successful passive
accept()events, revealing which server process just accepted an incoming TCP connection and from where.tcpretrans – watches live sockets for TCP retransmission events so you can spot packets being resent because of loss or congestion.
tcplife – tracks each TCP flow from open to close and prints a summary of its lifetime, including duration and bytes sent/received.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find this resource helpful. Keep an eye out for more updates and developments in eBPF in next week's newsletter.
Until then, keep 🐝-ing!
Warm regards, Teodor and Shankar
Several mistakes in the bpftrace one liners shown.
1. There is no kprobe available for tcp_select_window().
2. Even assuming you meant __tcp_select_window(), it has only one argument of type struct sock *sk.
3. There is no Linux kernel function called tcp_window_scaling().
4. The first kprobe argument is arg0 and not arg1.